Code is the new assembly language. Semantics are the new code.
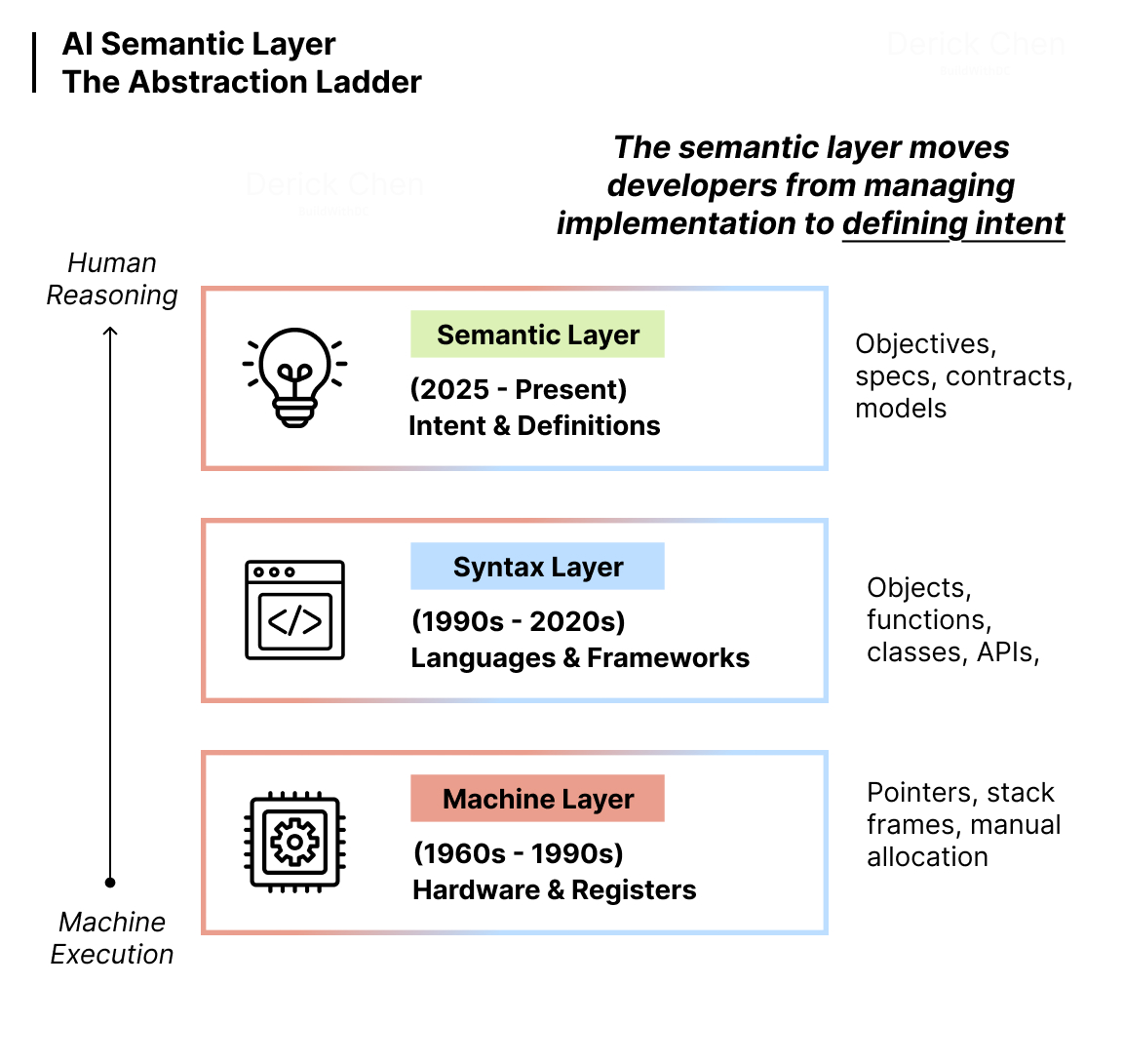
We’ve been climbing an abstraction ladder for decades. From assembly and C, where developers manipulated memory directly, to Java and Python, where we think in objects and functions. Each rung took us closer to how humans reason and further from how machines execute.
We’re climbing again.
But this time, the abstraction isn’t syntactic. It’s semantic. The shift isn’t about a new programming language or paradigm. It’s about where software is actually designed, verified, and eventually composed.
That layer isn’t code anymore. It’s the semantic layer—specifications, problem definitions, and architectural intent that exist before implementation. AI has made code generation trivial. The value has moved upstream. We’re still thinking about software in terms of code as the primary artifact. That’s already obsolete.
The Abstraction Ladder Link to heading
Every major transition in software development has been about ascending abstraction. Not just syntactic sugar—fundamental shifts in what developers engage with directly versus what the toolchain handles.
In the assembly and C era, developers managed memory explicitly. Pointers, stack frames, manual allocation and deallocation. You worked at the level of how the machine operated. The closer you were to the hardware, the more control you had—but also the more cognitive overhead.
General-purpose languages like Java, Python, and JavaScript abstracted that away. Garbage collection, dynamic typing, high-level data structures. Developers stopped thinking about memory addresses and started thinking about business logic. The machines got fast enough to handle the abstraction overhead. Developer productivity soared because the cognitive load dropped dramatically.
Each abstraction rung followed the same pattern: take something developers had to manage manually and make it automatic. Free up cognitive capacity for higher-order concerns. The abstraction succeeds when it lets you think at a level closer to the problem you’re solving rather than the mechanism of solution.
The current transition follows this pattern precisely. Code generation is becoming automatic. For roughly 90% of common implementation scenarios, with the LLM capabilities available in 2026, code generation is essentially a solved problem. What used to require careful crafting—translating intent into syntax, managing edge cases, ensuring consistency—can now be handled by AI. The cognitive overhead of implementation is collapsing.
So where does that leave us? What’s the new level of abstraction where developers operate?
Semantics to Build Link to heading
The semantic layer is where software construction now happens. Not in the code editor, but in the specifications, plans, and problem definitions that guide AI-driven implementation.
This is what spec-driven development enables. You don’t write code directly. You define the problem scope and boundaries—what needs to be built, what constraints apply, what quality bars must be met. The AI iterates on implementation within those boundaries. The spec is the authoritative artifact. Code becomes the compiled output.
Here’s where this diverges sharply from traditional documentation. Specs aren’t written after the fact to explain what was built. They’re created through your interaction with AI during the design phase and become the semantic context that guides generation. User stories, domain models, logical designs—these are semantic artifacts that capture meaning and structure before any code exists.
When you build composable specifications that reference each other—vertical specs for business capabilities, horizontal specs for technical layers—you’re constructing a semantic architecture. The specs define problem scope, not explicit behavior. This distinction matters. You’re not specifying “do X, then Y, then Z” in procedural detail. You’re specifying “here’s the problem space, here’s what success looks like, here’s what constraints apply.”
You might ask: doesn’t this only work for greenfield projects? What about the legacy systems that make up most of production software?
Start with the semantic layer for new features and services. Gradually encapsulate legacy components behind semantic interfaces—wrappers that describe what the legacy system does in semantic terms even if its internals remain unchanged. The semantic mesh I’ll describe later enables this hybrid approach: new components built from semantic specs, legacy components wrapped in semantic contracts.
The practical implication: software construction now happens at the semantic level. Implementation is downstream.
Semantics to Verify Link to heading
Guardrails aren’t just for deployed AI agents. They’re for the build pipeline.
Code reviews are bottlenecks. Pull requests stack up. Reviewers catch some issues, miss others. Review quality varies wildly depending on who’s available and how much time they have. The verification gap is real—AI can generate far faster than humans can meaningfully verify.
The solution isn’t just better code review practices. It’s automated semantic evaluation in the CI/CD pipeline. A semantic stage that validates artifacts against organizational best practices and compliance requirements before they compound into larger implementations.
Think of it as evolved linting. Style linters check formatting. Logic linters check for code smells and anti-patterns. Semantic linters check whether the artifact makes sense in context: Does this component respect domain boundaries? Does this data model meet compliance requirements? Does this service integration follow architectural standards?
You might ask how we measure “semantic correctness” when that sounds inherently subjective.
Fair question. The key is focusing on the verifiability of best practices and architectural principles. These patterns may not be perfectly contextual at first—early semantic validation might produce false positives or miss nuanced cases. But it’s a valid and increasingly effective way to evaluate custom engineering artifacts against organizational standards. Pattern matching improves over time as the validation rules get refined through feedback.
Here’s what this looks like in practice:
Semantic linting: Does this new service respect the bounded contexts defined in the domain model? Does it introduce dependencies that violate the architectural constraints?
Compliance checking: Does this data model include personally identifiable information without the required audit trails? Does this API expose data in ways that violate GDPR?
Architecture validation: Does this implementation introduce cyclic dependencies? Does it bypass the standard authentication layer?
These are checkable patterns. Not vague aspirations, but concrete rules encoded from organizational knowledge. The mechanism is meta-validation—using separate LLM instances or hooks in your agentic building tools with organizational best practices as context to verify artifacts at each stage. When specs are generated, validate them against appropriate architectural principles. When code is generated, validate it against both specs and standards. Catch deviations early, before they propagate.
This approach is still emerging. Tools will evolve. Patterns will solidify. But the direction is clear: verification moves from manual human review to automated semantic gates that operate continuously throughout the development cycle.
The Semantic Context Layer Link to heading
But doesn’t documentation always go stale? Aren’t specs just another form of documentation that will rot the moment implementation diverges?
That’s the pattern we’ve seen for decades and also in the early days when coding agents littered redundant MD files all over the repo. Write detailed design docs upfront. Implement. Ship. Six months later, the docs are wrong and nobody updates them because they’re not part of the workflow.
The semantic layer is different because it’s actively consumed, not passively referenced.
As I described in Effective Context Window, source code is semantically sparse. You can communicate the same business logic in plain English using roughly half the tokens it takes to express in code. Code tells machines what to execute. Comments tell humans why decisions were made. The semantic layer tells both humans and AI the meaning and structure—the conceptual architecture that underlies implementation.
When you iterate with AI—refining requirements, adjusting domain boundaries, clarifying constraints—those conversations produce semantic artifacts. User stories get refined. Domain models get updated. Architectural decisions get documented. These aren’t separate from development; they’re the primary artifacts of development. Code is what gets generated downstream.
Here’s why specs don’t drift: specs become first-class citizens. You should never directly modify code with AI without consulting or updating specs first. The spec is the authoritative artifact. When you want to make a change, you update the spec, then regenerate or refactor the implementation to match. The workflow enforces this discipline. Code that doesn’t match its spec becomes immediately visible because the spec is what guides generation.
The specs created through AI iteration cycles become a semantic context layer that’s reused across the application’s lifecycle. Need to onboard a new engineer? They read the domain model and logical design—dense, semantic representations that convey far more understanding per unit of reading time than reverse-engineering from code. Need to add a feature? You start from the existing semantic context, not from reading through thousands of lines of implementation.
The semantic layer captures intricate application details and business logic that would take hours to extract from code in minutes of semantic reading. It’s the organizational asset that appreciates over time as more context gets encoded. Not static documentation, but a living knowledge base that AI and humans both work from.
Once an organization establishes a methodology and spec architecture, every project can be expected to have similar-natured specs in designated places. Domain models live here. Logical designs live there. API contracts follow this structure. This consistency enables knowledge sharing across projects without having to process large chunks of raw implementation code. An engineer joining a new project can read its semantic layer and understand the system’s architecture, domain boundaries, and integration patterns—without ever opening the codebase.
The Semantic Mesh Link to heading
Now take that concept across service boundaries.
A semantic mesh is a network of semantic specifications describing integration patterns, data contracts, and behavioral expectations across distributed systems. Instead of just API schemas—which tell you the shape of data but not its meaning—you have semantic contracts that capture what services do, what guarantees they provide, and how they’re meant to be composed.
This tackles the higher-order integration issues that are the most expensive and time-consuming to discover and fix. The bugs that live between services. The implicit assumptions about data consistency. The edge cases in distributed transactions that only manifest under load.
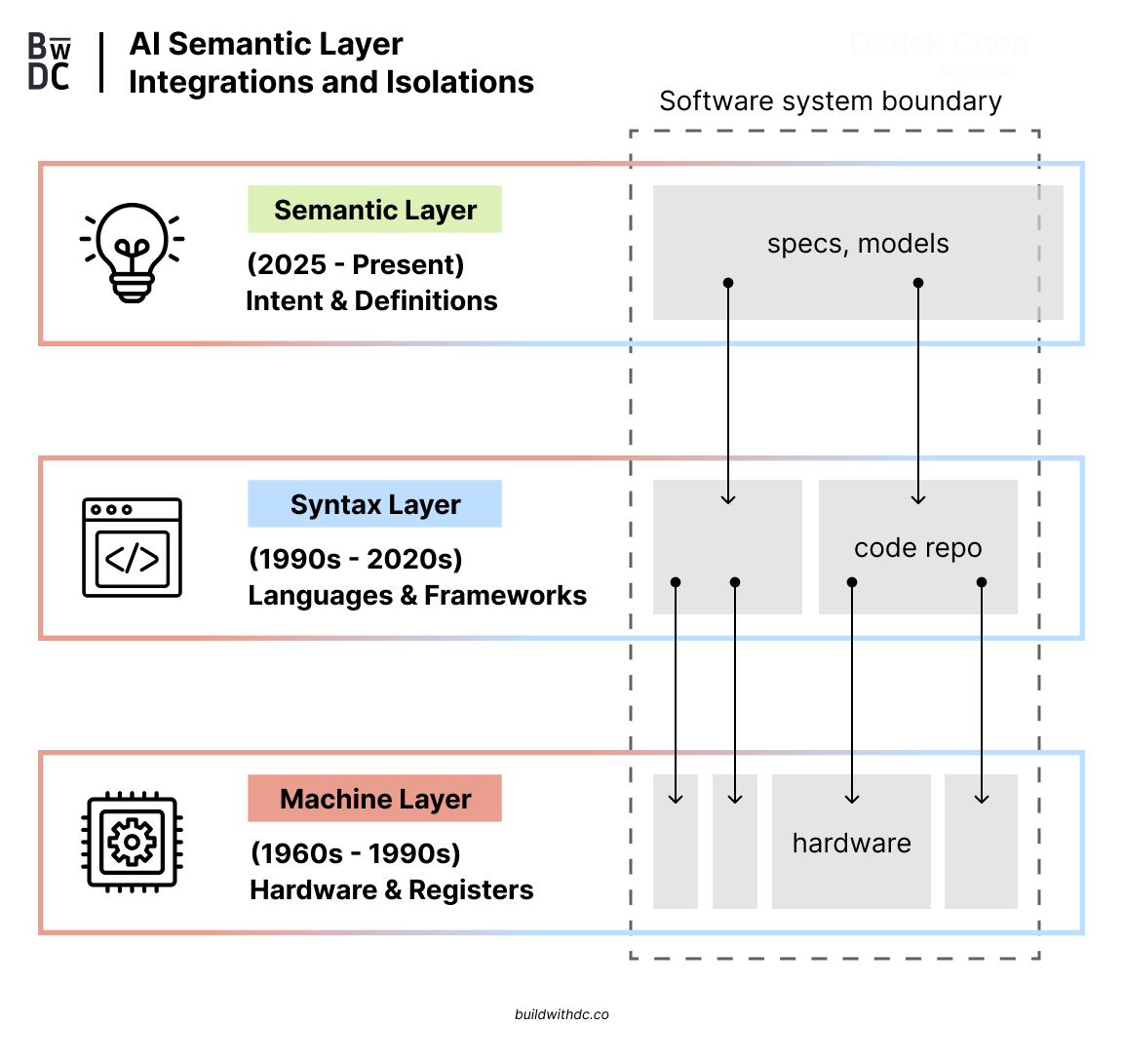
When service teams publish semantic specs that describe not just endpoints but behavioral contracts—what happens under failure, what ordering guarantees exist, what eventual consistency means in context—integration tests become semantic compatibility checks. Does Service A’s expectation about data freshness align with Service B’s guarantee? Does the retry logic in Service C match the idempotency contract of Service D?
These questions can be validated semantically before any integration code is written. You’re verifying contracts at the semantic level, catching incompatibilities early.
Here’s where composable specifications extend across service boundaries. A service’s semantic spec references the semantic specs of services it depends on. Cross-service transaction patterns are described semantically—not just “call these APIs in sequence” but “here’s the semantic meaning of this distributed operation, here’s how partial failures are handled, here’s what invariants must hold.”
When one service evolves, semantic validation catches where downstream consumers’ assumptions break. The mesh provides the connective tissue that makes distributed system evolution safer.
This Is Not MDD Link to heading
Here’s the elephant in the room: MDD failed. UML/MDA failed. Why should this be different?
Valid question. Let’s be direct about the distinction.
Model-Driven Development tried to explicitly define behaviors upfront. You specified what code should do in excruciating procedural detail—sequence diagrams, activity flows, state machines. The models were meant to be complete enough that code generators could produce working implementations mechanically. This was big design upfront taken to its logical extreme.
It failed for two reasons. First, defining behavior completely upfront is nearly impossible for non-trivial systems. The complexity explodes. Edge cases multiply. The models become as complex as code but harder to reason about. Second, the code generators were deterministic and brittle. They could handle the happy path but broke on anything the model didn’t explicitly anticipate.
The semantic layer defines problem scope and boundaries, not explicit behaviors. You’re not specifying “do X, then Y, then Z.” You’re specifying “here’s the problem space, here’s what success looks like, here’s what constraints apply, here’s what quality bars must be met.” That’s a fundamentally different contract.
LLMs bridge the gap between semantic definition and implementation in ways deterministic code generators couldn’t. LLMs are probabilistic and adaptive. They handle nuance. They can reason about incomplete specifications and infer reasonable implementations. They don’t need every edge case explicitly modeled—they can generate plausible handling and then be corrected through iteration.
You might think this sounds like big design upfront under a different name.
It’s not. Design happens incrementally, but intentionally. You don’t define the entire system semantically before writing any code. You define one domain, implement it, validate it, learn from it, then define the next domain. The semantic artifacts evolve with the system. They’re refined through implementation feedback, not frozen upfront.
This is adaptive design, not predictive design. The semantic layer provides just enough structure to guide implementation without over-constraining it. MDD failed because it tried to predict everything. The semantic layer succeeds by defining boundaries within which AI-driven iteration happens.
The other critical difference: MDD tried to eliminate coding. The semantic layer embraces coding but changes what’s primary. Code is still essential—but it’s the output of a semantic design process, not the starting point.
The Future: Token-Efficient Logic and Asynchronous Collaboration Link to heading
As teams operate at the semantic level, something interesting emerges: token-efficient representations of logic.
Remember, semantics are more efficient than code. As I noted earlier, describing business logic in structured English takes roughly half the tokens it takes to express the same logic in code. That efficiency compounds when you’re working with complex systems. You can convey architectural intent, domain boundaries, and integration patterns in a fraction of the tokens it would take to read through implementations.
This isn’t just a nice-to-have. It’s foundational for the kind of collaboration that’s coming: asynchronous agentic collaboration.
In The Future of Software Engineering, I described the shift from synchronous development (humans directly writing code) to asynchronous orchestration (AI agents building software within guardrails set by humans). That future requires a coordination mechanism that’s more efficient than passing code between agents.
The semantic mesh provides that mechanism. AI agents don’t coordinate by reading each other’s code. They coordinate by reading semantic artifacts—the problem definitions, constraints, and contracts that describe what components do without specifying how. This preserves verifiability (you can check whether an implementation matches its semantic contract) while dramatically reducing the communication overhead.
For most systems, teams will operate at the semantic level. Define the problem, set the quality bars, validate the output. Performance-critical systems—real-time trading platforms, embedded systems, high-throughput data pipelines—will still require engineers to “open the hood” and optimize at the lower levels. But that becomes the exception, not the default.
The practical implication for engineering teams: your primary artifacts shift from code to semantic specifications. Your primary skills shift from implementation to problem definition, trade off decisions and system verification. Software engineers become agentic orchestrators—defining the structure, boundaries, and contracts within which AI agents execute implementation.
This is the missing foundation for building high-complexity software systems at scale with AI. Not “prompt engineer a feature,” but “architect a semantic layer that guides autonomous implementation and ensures system-wide coherence.”
The Semantic Shift Link to heading
Abstraction layers evolve to match how we think, not how machines execute. Memory management was essential when compute was scarce. Syntax abstraction became viable when machines got fast enough to handle interpretation overhead. Semantic abstraction becomes necessary when implementation becomes trivially cheap.
We’re at that inflection point. Code generation is essentially unlimited. The bottleneck has moved. The value is now in defining problems correctly, setting appropriate constraints, and verifying that what’s built matches what was intended.
Many teams I work with are already building with semantic capabilities, whether they recognize it explicitly or not. Every time you write a detailed problem specification for AI to implement, you’re working at the semantic level. Every time you validate generated code against architectural principles, you’re doing semantic verification. Every time you document service contracts that go beyond API schemas, you’re building the semantic mesh.
The question isn’t whether the semantic layer will become primary. It’s how deliberately you architect it.
Code becomes the compiled output of semantic thinking. The primary artifacts—the things you review, version, maintain, and evolve—are semantic specifications. The primary skills—the capabilities that can’t be easily automated—are problem definition, constraint setting, system architecture, and semantic verification.
The shift has started. The teams that recognize it and adapt deliberately will build better systems faster. The teams that resist will keep optimizing code generation while wondering why their systems aren’t getting better.
The semantic layer isn’t coming. It’s already here. The only question is how deliberately you architect it.