The double-edged sword of large context windows
In the early days of using ChatGPT for coding, loading instructions and resources into the web based chat interface was the struggle. Having to copy and paste code snippets while also representing the project structure one key stroke at a time eroded much of the productivity gained.
Now, two years later with newer models like Claude 4 with 200k token context windows size, coupled with agentic coding assistant, we are still not seeing the results we expect. Models have bigger contexts now, but now we are wrangling the problem of effective context.
The Nature of Source Code Link to heading
To understand how we can maintain effective context while interacting with GenAI coding companions for software development, we first must analyse the nature of source code.
Source code in general are declarative in nature. Rigid and overly verbose grammatical structure was the foundation for machine interpretable languages. We have significantly abstracted the syntax from Assembly to Python, but source code in general still are extremely verbose.
Consider this simple function in Java:
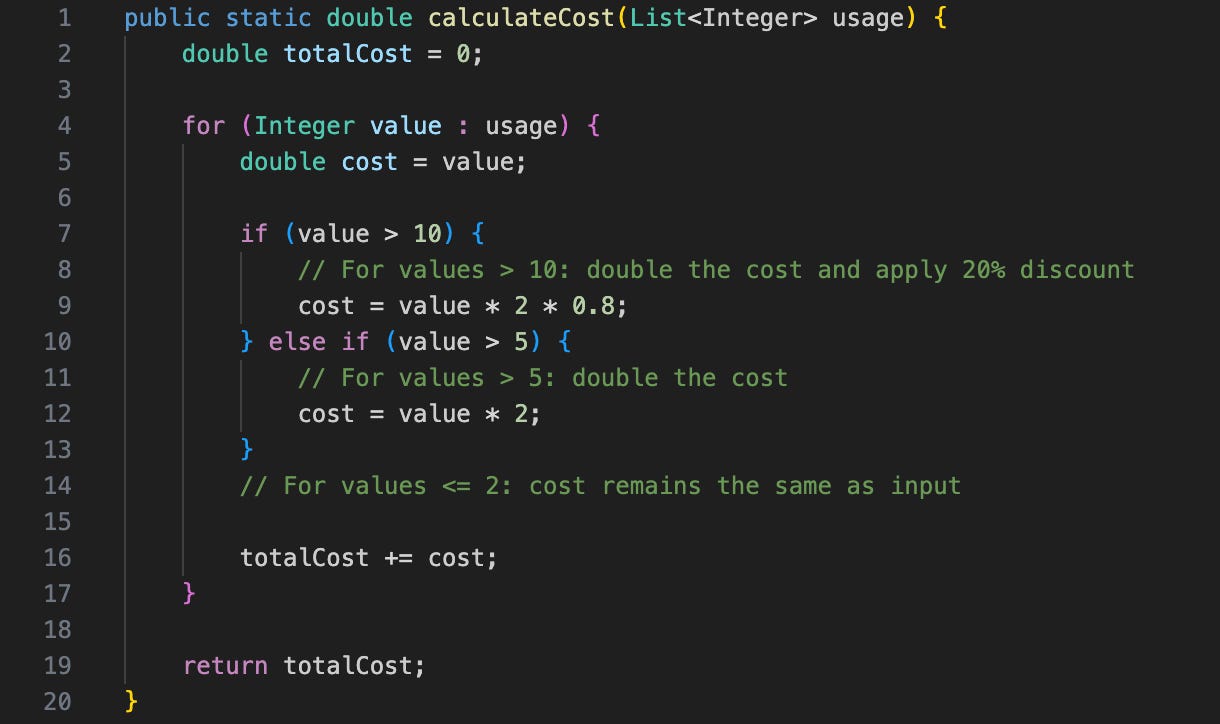 If we were to describe this function in English to convey the same meaning:
If we were to describe this function in English to convey the same meaning:
The function calculates total service cost by processing an array of usage values. Each value ≤ 2 counts at face value, values > 5 are doubled, and values > 10 are doubled then discounted by 20%. The function iterates once through the input list, applies these rules to each element, and returns the sum.But if we compare the number of tokens required to represent this business logic, in source code format vs in English description based on OpenAI’s tokenizer for GPT-4o:
Source code - 139 tokens, 542 characters
English description - 66 tokens, 304 characters
The plain English version takes up only half as many tokens for an auto-regressive generative model. Hence, it is fair to conclude that source code is sparse in semantic meaning.
In that case, newer models like Claude 4 with 200k token context window should significantly improve the effectiveness of complex coding tasks. Yes indeed, but still not quite at the level that we would hope for.
The Reality of Large Context Windows Link to heading
While many model providers have extended the context window size to 200k, and in some cases even 2000k tokens, we are seeing a general and significant decrease in answer accuracy beyond 64k to 128k tokens as illustrated by Figure 1. Crucial details are still lost in large contexts.
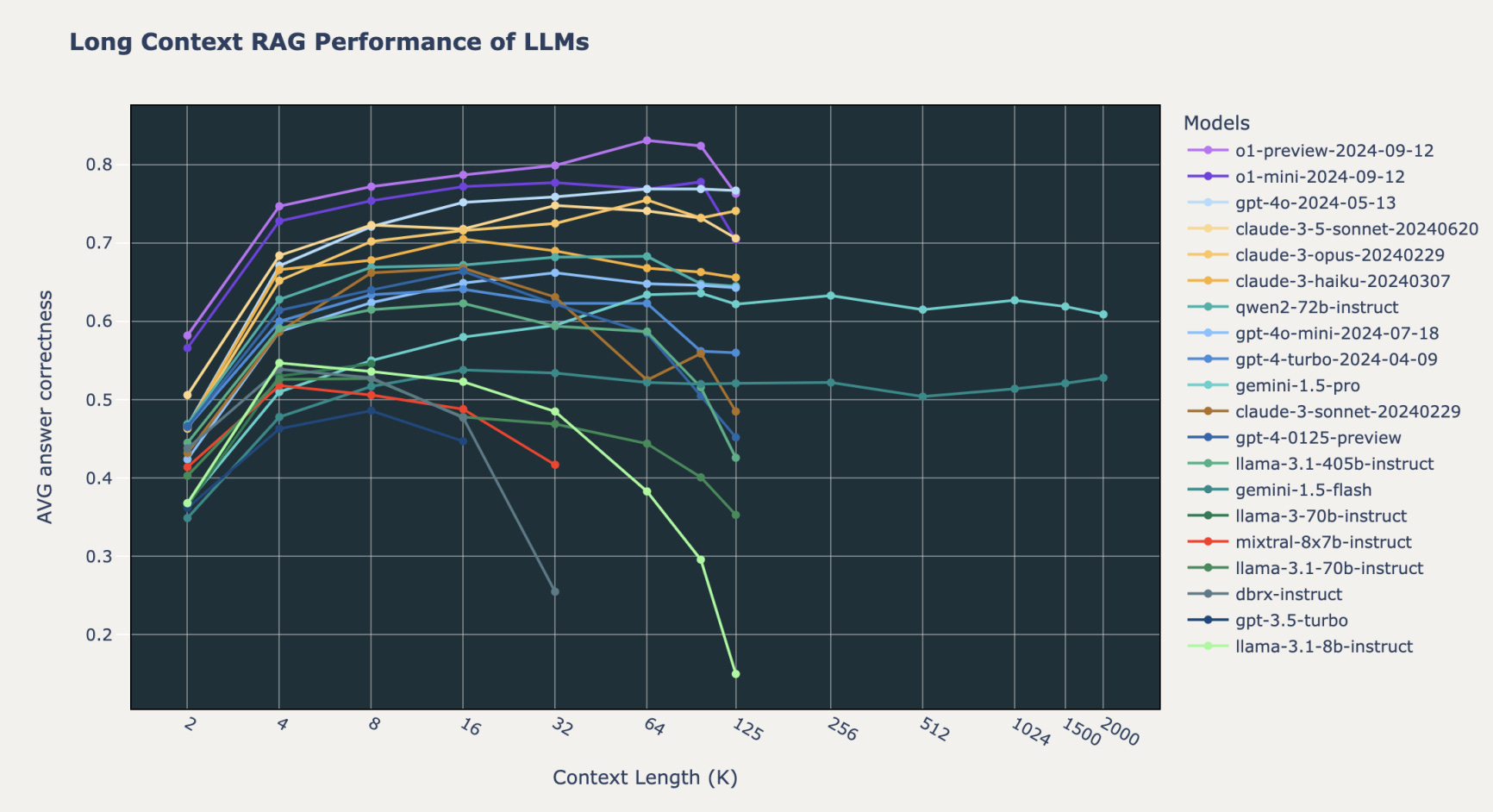 Fig 1. Generation accuracy reduces as context size increases (Leng et al., 2024)As we have established that source code has sparse semantic meaning, this means that throwing your entire code base to a 200k context window language model today will most likely not yield the exact implementations you are looking for. Not to mention that such a strategy can get very costly, very quickly when vibe coding with an AI-Managed approach.
Fig 1. Generation accuracy reduces as context size increases (Leng et al., 2024)As we have established that source code has sparse semantic meaning, this means that throwing your entire code base to a 200k context window language model today will most likely not yield the exact implementations you are looking for. Not to mention that such a strategy can get very costly, very quickly when vibe coding with an AI-Managed approach.
Additionally, most Large Language Model (LLM) clients and software assistants do not currently offer a user-friendly, context micro-management features. Some coding assistants like Amazon Q CLI offers the /compact command to summarise the current session context to reduce the number of tokens, and almost all offer a way to clear the entire session.
This makes session context management a skill that need to be learned by software engineers. Session context needs to be cleared tactically when switching context to an unrelated task. Keep the context clean and task focused, preferably within 128k tokens. This is when summarised documentation on classes, modules and integration patterns come in to save the day — especially for peripheral implementations that are not in scope for the current task at hand.
Clear session when switching task
Keep session task focused, ideally under 128k tokens
Appropriately leverage written documents to reduce context size
We have been exploring the limitations of using Generative AI for delivering complex software systems so far. Previously, we discussed how the popular methods of vibe coding were undesirable, and in this post, we evaluated the limitations of the underlying technologies.
We need a two-part solution: both from the technology and the practice angles. Stay tuned as I introduce a consistency method that I helped shape from its earliest stages to help large enterprises 30x their software delivery speed.
References Link to heading
Leng, Q., Portes, J., Havens, S., Carbin, M., & Zaharia, M. (2024, November 5). Long Context RAG Performance of Large Language Models. Long context rag performance of large language models. https://arxiv.org/html/2411.03538v1